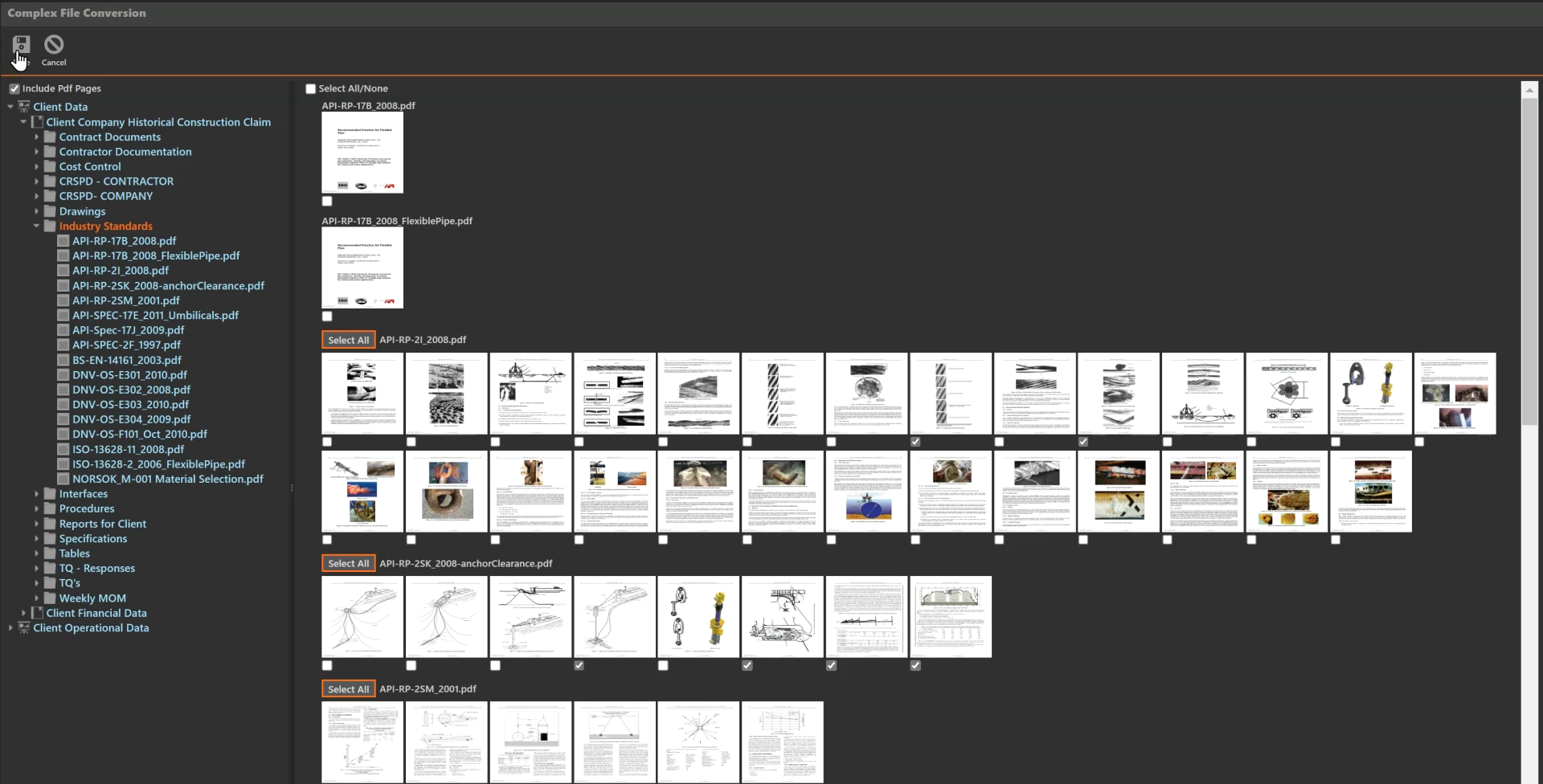
Efficient Review
Only review relevant pages
The Expede AI interface displays only the document pages that contain complex content so the user can quickly determine which content needs to be processed and extracted. Just individual pages or all complex pages within a document can be quickly selected.
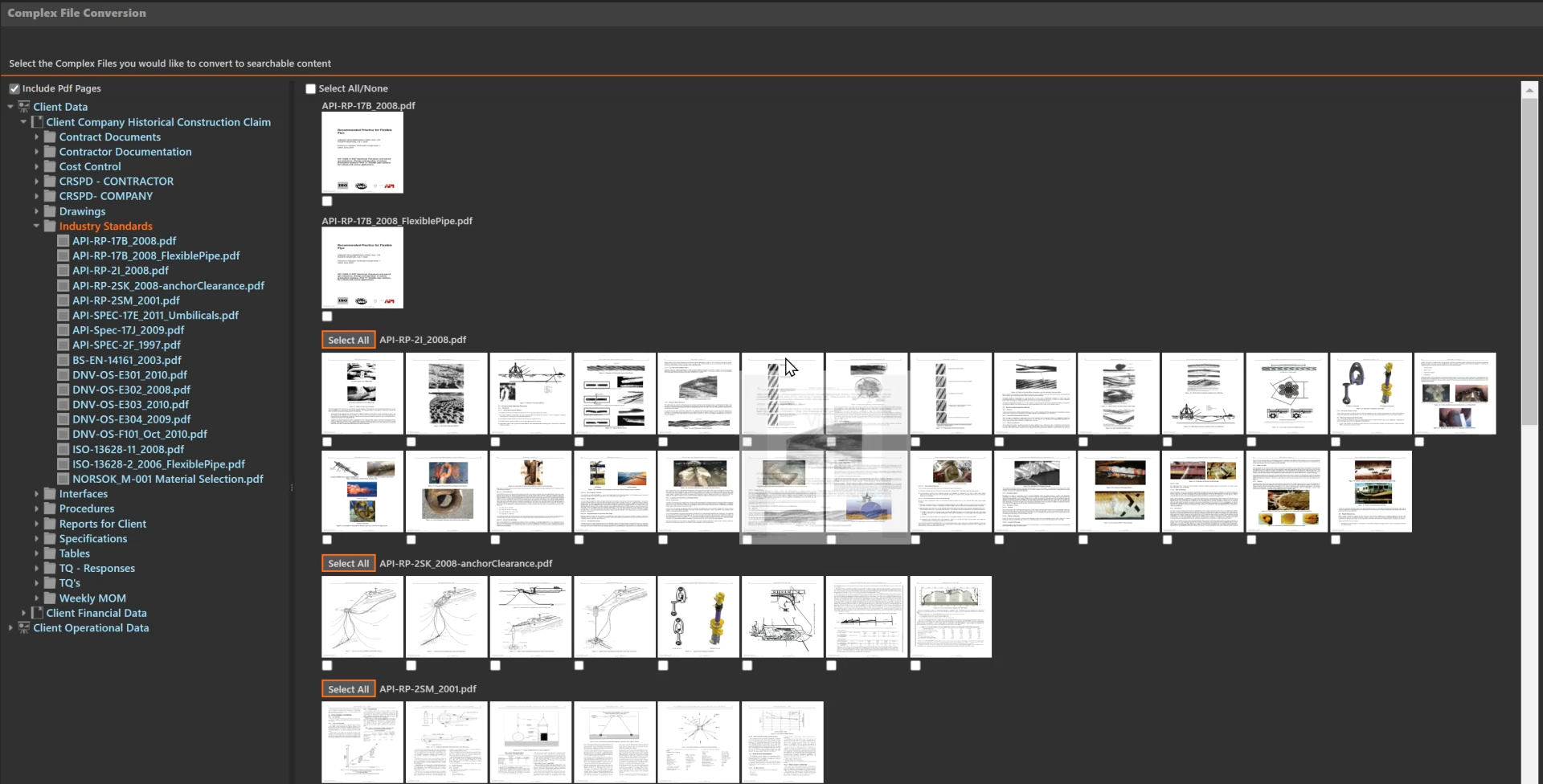
Single Streamlined Interface
Zoom into the Detail
Without leaving the Expede AI interface, users can zoom into selected pages to review the content and determine if it requires further processing. Users can also click into the document itself to review in context and then easily return to the AI interface. This enables users to efficiently review large volumes of information and only select what is needed.
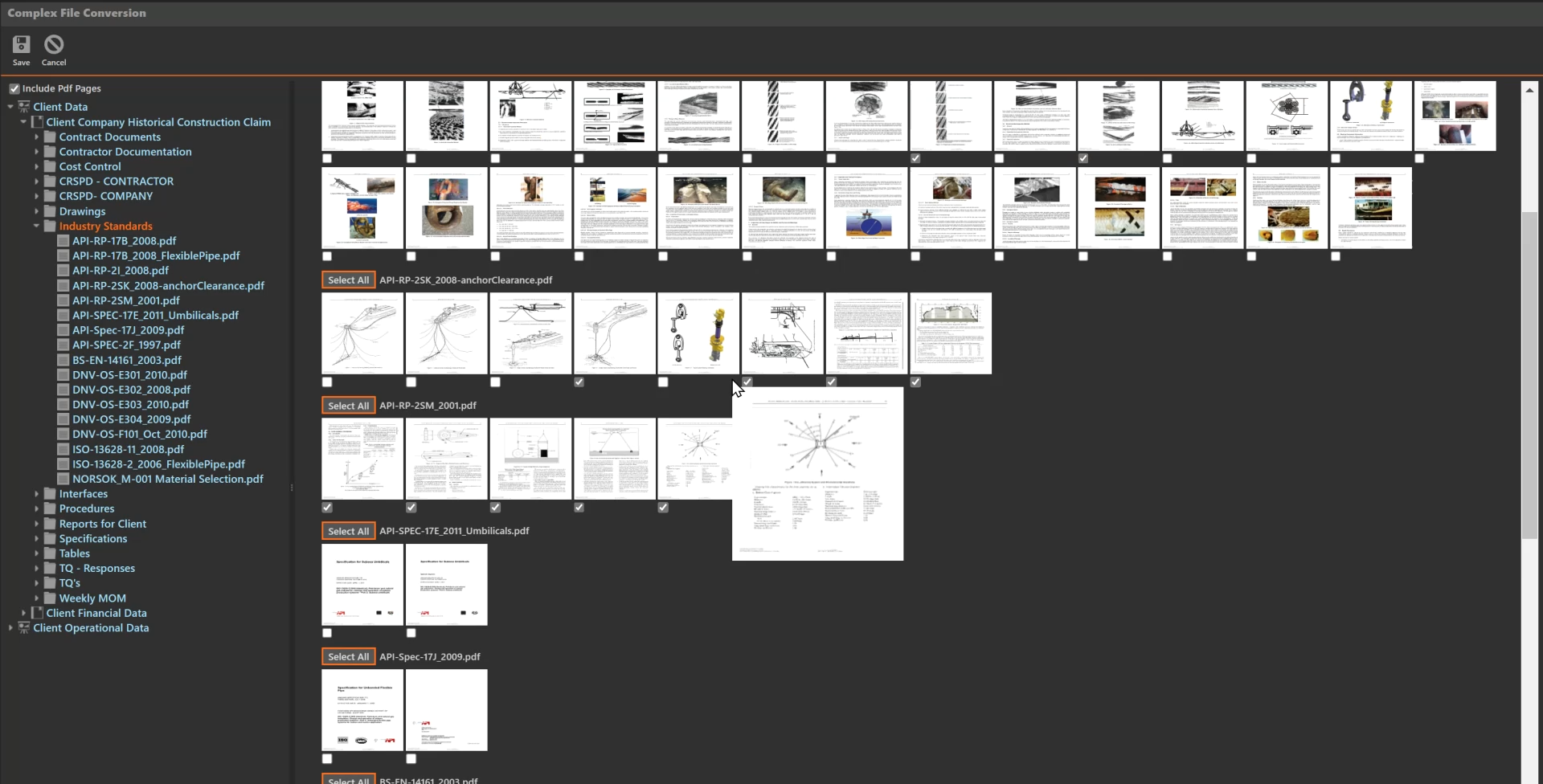
Immediately Available
Realtime Processing
Once a review has been finished and saved, Expede undertakes real-time page processing which passes each selected page through a series of 7 data extraction and validation processes to ensure accurate data extraction. The extracted data is associated with the origin page and immediately added to the database for searching and data management. Typically, 50,000 pages can be processed per hour.